
The Geek Out: Inception
by Kyle Downey, CEO & Co-founder - 02 Apr 2022

What is the most important attribute of a product development environment? There are a lot of possibilities here, but over the years one attribute keeps bubbling to the top in my experience: short feedback loops. Developers are constantly iterating in partnership with the product team, with shuttles flying across the loom at multiple levels as the developer refines her code; as the product owner refines his understanding of the client problems, ideally in a responsive feedback loop with the client. The goal is not to avoid mistakes; the goal is to learn and keep from going down a long path to nowhere before realizing the solution will not work, the product is not commercially viable, or the feature is impossible to use and understand.
The very best quant development teams I worked with over the years refused to tolerate delays in getting feedback. They designed their systems and tools to optimize for the shorted possible cycle when conducting trials, whether it was the build process to deploy new code or the runtime of a multi-year backtest. They would throw massive compute grids at the problem and quant teams that in other contexts would take a lot of shortcuts which made the engineers queasy would spend days optimizing a piece of code so they could get a result they could evaluate in 5 minutes instead of 15 minutes. Engineers who worked on HFT algo trading systems for traders who could not care less about unit testing would insist on time spent on a fully-automated test suite which would break as soon as new code hit the master branch so they could control the risks of releasing to production in some cases three to five times a week.
Why is this? Quantitative finance is at heart built on the scientific method. The unit of work for a quant is not a model or a line of code, but an experiment. As the old saying goes, telling people — even PhD’s in mathematical finance — to “think faster” is generally not a winning strategy for increasing productivity. Thus it’s generally hard to get more out of a given experiment. The only route to higher productivity is to run more experiments, which means that the cycle time, the time to set up, run and evaluate the results of the experiment, is an incredibly important variable in a quant’s productivity. If you have two hedge funds, one which pays brilliant and hard-to-hire analysts to sit and wait, and another that pays them to run many more experiments, the latter will outperform the former. An experimental run, whether it passes or fails, is a learning opportunity, so more runs mean more learning.
While software development teams have to be careful not to forget that their tooling is in the service of product development, poor tooling can also undermine progress on delivering the best possible product. The DevSecOps team at Cloudwall and our partners in Research all came from backgrounds where there was no question that we would have to spend some time up front creating an environment that would enable us to move at 200 miles per hour later, even if that meant some time upfront on code that not a single customer would ever see. Our ambition was nothing less than to have a production cycle time measured in days, not weeks or months, with near 24x7 uptime and dial-tone reliability, so in the face of the rapid changes in digital assets we can get model changes, novel data sources or system improvements for the Serenity digital asset risk platform in the hands of our customers fast.
The quant development environment that resulted, Inception, is our answer to this problem. The setup is the brainchild of our brilliant CTO, Makas Lau Tzavellas, and builds on his experience leading the Big Data engineering team at Binance prior to Cloudwall.
A Fully Remote Operation
As a small start-up launched during a pandemic, Cloudwall had no choice but to begin fully-remote. And we are global: we have team members in NYC, Ireland, Belarus, Singapore and Japan. While we have virtual office space at 40 Wall Street for meetings, everyone is usually working at home, and as we never had an office everyone began working with their personal computers. This very quickly became a problem: Python and Docker do not work well on the Apple M1 chips, and we had an incoming Research team member who had an M1 laptop. Short of shipping her a new machine which the company did not have the resources to buy at that stage, we needed a way to get her up and running ASAP.
We had adopted Microsoft’s Azure early on for our cloud platform, and our CTO came across an interesting feature: DevTest Labs. This is a managed VM pool which lets you very quickly spin up VM’s from recipes. By setting up a DevTest Lab in each geographical region, we could have Linux machines in close proximity to everyone. Even better, the economics were favorable: we could get everyone a dedicated VM for about $800 a month, and as we are part of the Microsoft for Startups program, this would come out of our Azure cloud credits rather than the company’s limited cash in the early days — although GitHub Codespaces and other cloud IDE offerings could offer something similar, GitHub Codespaces was not covered by the cloud credits, and the cost was prohibitive for a growing team with limited resources.
All we needed was a way to use these VM’s from the developer desktops. If we could do that then it would no longer matter what the developer had at home: Windows, Mac Intel, Mac M1, Linux: every developer’s code would be running on a cloned VM from a centrally-managed recipe using the exact same version of Linux. While large companies have the luxury — and burden — of having nearly-identical desktop machines running centrally-managed Windows deployments that change rarely, we had a zoo of different environments to support.
A Dream Within a Dream
In the movie Inception a team of hackers descends into the depths of a multinational executive’s subconscious, aiming to plant an idea deep inside, with each level a dream within a dream. The Inception developer environment is similarly layered:
- Outermost layer: Visual Studio Code running on the developer’s machine — ultimately moving to a cloud-based jump host based on Windows 11, accessed via RDP
- Cloud VM: a standard Linux VM running the Docker daemon, hosted in a zone close to the developer to reduce latency
- VS Code Server: a server-side partner to the developer’s VS Code client, packaged as a Docker container running on the VM
- Docker-in-Docker: a Docker daemon inside the VS Code Server’s devcontainer running Minikube for Kubernetes support
- Serenity & its infrastructure: Docker images of our code orchestrated by Kubernetes
At a high level it looks like this:
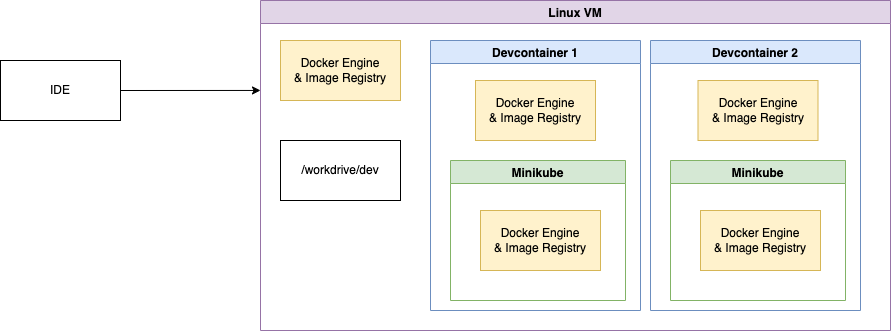
though technically there’s a bit more at work here. For instance, to ensure the developer’s local Azure login tokens are visible inside the depths of Inception, we need to do a bit of magic with Docker Compose and mounts:
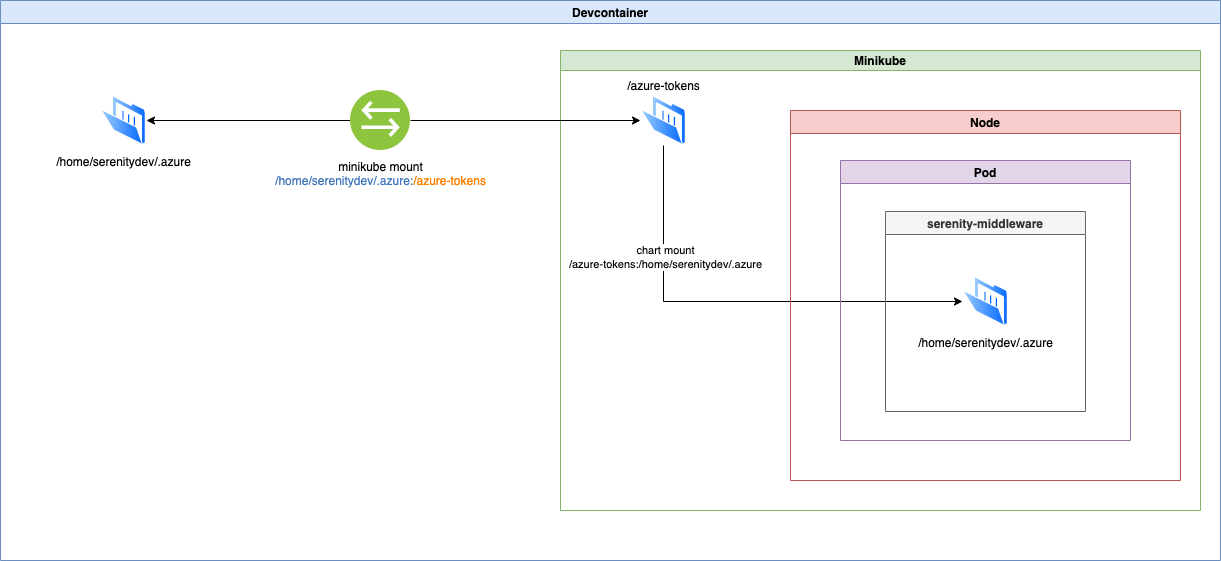
Taking a step back: why on earth would we do this? Why not just run a Windows VM with Visual Studio Code in the cloud and be done with it, and just let the developer run and debug local Python processes using a Windows build of Python.
The way I think about this is about front-to-back and lateral symmetry. By front-to-back symmetry I mean that every environment — the local development environment plus dev, staging, beta and production in the cloud — is identical, differing only in the version of the code each is running plus any concessions to the specifics of that local environment, e.g. using a storage emulator rather than cloud storage in the local environment, or supporting remote debugging in local only. This matters: if the developer builds and tests code on Windows or a Mac and then pushes it to the cloud, the very first time that code is tested in a realistic configuration on Linux is when it has been deployed. This introduced delay: every time something breaks because it’s not quite the same from one environment to another, the developer has to debug, rebuild, redeploy and try again. In the worst cases and with poorly-designed build and deploy setups lacking automation or attention to turnaround time, this can cause hours to be lost.
Lateral symmetry is about the similarity of one developer’s local development environment to another. Over the years this has been another bugbear: the classic “it works on my machine” which no one can figure out until you find out that one developer has Python 3.8.12 and the other has Python 3.8.13, and the behavior is slightly different. So long as everyone’s code is sync’d to GitHub, this should never happen with Inception. Every single tool, VS Code plugin, operating system library, etc. is defined in code, in the devcontainer.json and its associated Dockerfile. Want to upgrade everyone to Python 3.9? Change the configuration, push, and have everyone git pull. There is no more running around to look over a junior developer’s shoulder while they fix their setup, no more wiki sites documenting all the steps to get the “right” setup before you start work. We can onboard new developers rapidly and once they are here we can have a much greater comfort that when things go wrong it’s generally due to a code change, not a local setup. Git history becomes the authority for every change, including developer tooling.
However, you may be asking yourself about that very last dream within a dream: the Docker container running Minikube inside the devcontainer. If we already have a uniform Dockerfile and Linux installation with all the tools, why do we need that level? This is because the local environment is a special case of ensuring front-to-back symmetry, and most of the scripting we built around VS Code for Inception was related to this. We wanted deployment and running of the microservices and data pipelines behind Serenity to be as close as humanly possible to a proper Azure Kubernetes Service (AKS) deployment in the cloud. This means even the simple act of starting up a Python server goes through Kubernetes. We focused our energy on making this as fast as possible, introducing not only local mounting of the code into the Docker container to avoid a rebuild but also hot-reload of Python code when debugging. So long as Helm charts and other configurations do not change, we can start up Minikube in the morning, deploy Serenity once, and then run it all day; the servers bounce and reload code as the developer makes changes, in real time. Most of the time the turnaround time is very close to the time to just stop and restart a Python process in Visual Studio Code on your desktop. It’s not perfect, but as a balance between ensuring maximum symmetry across both critical axes and nimbleness, it is a leap forward from anything I have worked with in the last 25 years.
Other Benefits
I have outlined most of what we hoped to get out of the Inception set-up, but there are a few others we observed once we got up and running:
- In a tradition set-up, scaling the developer’s environment up or down requires replacing a physical machine. If the developer needs more disk space, RAM or CPU to run some resource heavy testing locally, this could mean weeks or even months of waiting, and once the new, workstation-grade machine has been bought, it stays on the books depreciating even if the heavier compute was only needed for a short project. With DevTestLab, you can just resize the VM without even the need to build a new VM. Done? Scale it back down. The accountants reading this may have a quibble about cash out the door vs. assets not being apples-to-apples, and cashflow management at startups is critical, but the single largest expense at any software startup is the R&D team, and making them even 10% more productive almost always pays off compared to changes in the monthly recurring cloud costs.
- Complex systems often involve specialists working on different subsystems; not everybody works on every piece, but since the system is distributed, an integration test requires you to run every piece. Our UI developer expressed that this is the first time ever he could run a full server locally — even running a shared branch with the server developer. This enabled strong collaboration between the client and server developers to fine tune even before merging.
- One long-standing gripe when I worked in a Wall Street IT environment was not only did the local environment not have the full supporting infrastructure, but even lower-tier environments like dev and QA often did not have the full infrastructure either. Lacking monitoring and alerting and other SRE-type tooling locally or in dev means you don’t really test these integrations until the code is deployed to a higher tier, and in the worst cases certain features are only in production. In my past experience differences in alerting infrastructure between QA and production led to “silent” failures, for instance. With Inception, everything is deployable to any environment, including local, so if you have a hefty VM and want to test Grafana, Prometheus, the EFK stack for logging, etc., you can.
- Because the entire setup — Linux version, tooling, supporting libraries, etc. — is stored as code, experimenting locally with new setups or versions is very low risk and low cost. You just change the settings, rebuild the devcontainer, and try it out. Bad idea? Just git reset and rebuild your container and be back in business in less than 2 minutes, assuming like us you use pre-built containers in your Docker registry. This encourages risk-taking and experimentation; a developer no longer risks breaking her own environment for a day just to try out some new piece of automation to see if it improves productivity.
Tying It All Together
So now we have this wonderful setup where every developer in the team has matching environments, and those local environments match the higher-level environments in the cloud to the greatest extent possible. How then do we move new version of the code from one tier to the next, preserving our core principles of repeatability and automation? It would be a shame if our local and cloud development environments differed simply because someone had set up resources by hand and forget a setting. This means we need proper CI/CD pipelines tying everything together, and ideally as much as possible should happen hands-free. Parts of this are still a work in progress for us as we prepare for our beta this summer, but the key elements are all there and in use by our engineering team every day.
The glue is mostly in Azure DevOps Pipelines, but the key pieces — common across local and cloud environments — are based on ArgoCD, which lets us automate Helm upgrades and provides a Web front-end both locally and in the cloud to deploy components safely and repeatedly. We also use Microsoft’s Bicep to script Azure cloud resource creation, though this might be replaced by something more portable and well-known like Terraform in the future.
The final state flow will look something like this:
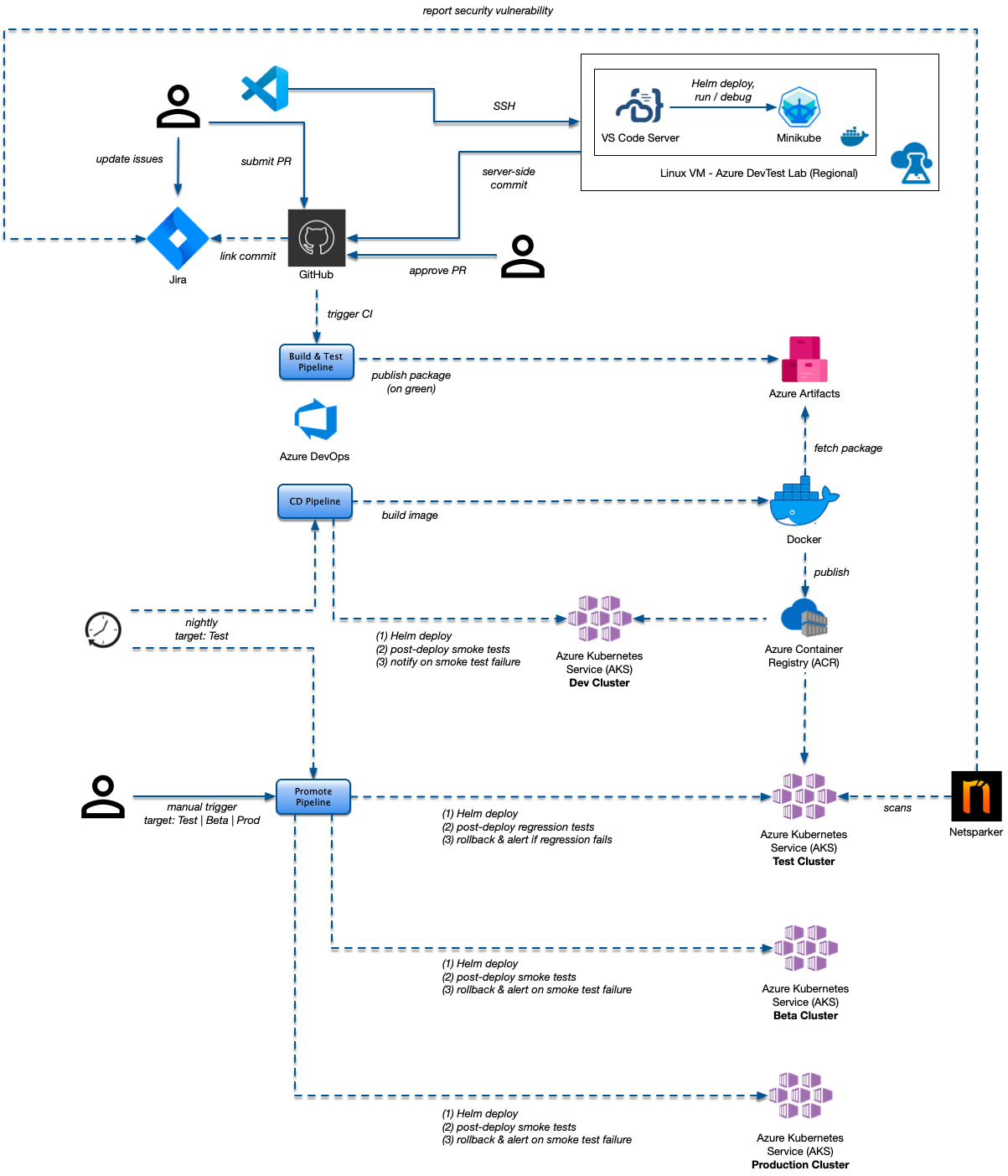
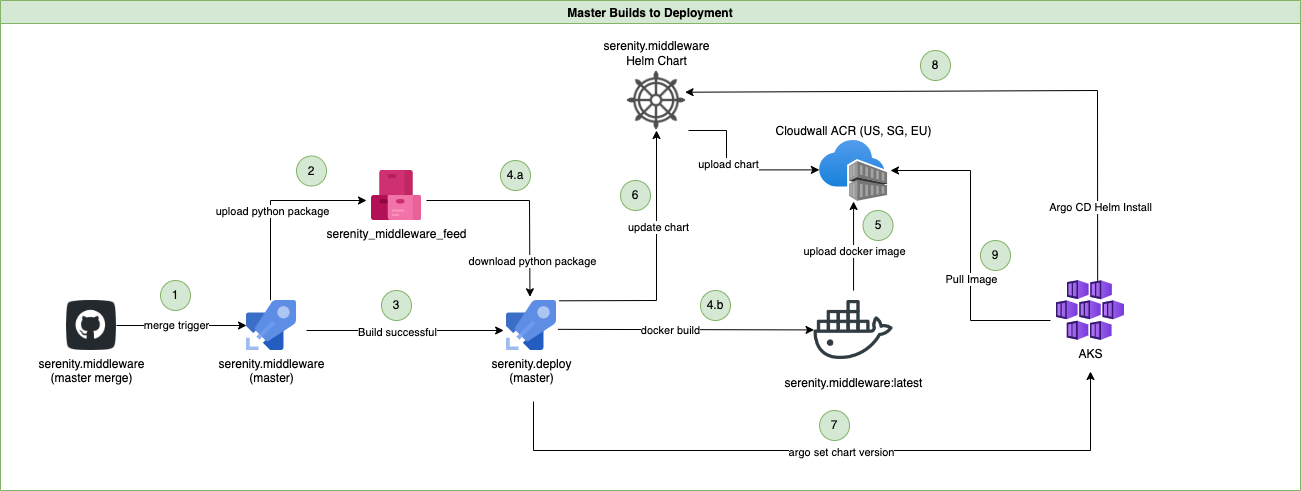
And the key pieces that handle deployment look like this — coordinating GitHub, Azure Artifacts, Azure DevOps Pipelines, Azure Container Repository (ACR), the Docker build and of course Azure Kubernetes Services (AKS) for the final deployment:
No development environment is perfect, you need to take care to reuse as much as you can to avoid over-engineering, and a number of the pieces we chose to pull together here are fairly leading-edge; things can and do still go wrong. But we think having started in the early days with this discipline and focus on the developer’s experience and productivity will serve the company very well in the years ahead.